
Abstract
Generative AI has dramatically reduced the cost of software development, leading many to question whether traditional enterprise technology approaches, buying commercial off-the-shelf software, minimising customisation, and maintaining architectural governance, still make sense. This paper argues they do, but for different reasons than we think. By examining three foundational forces that shaped enterprise IT (cost of production, cost of knowledge, and cost of comprehension), and proposing a simple cost model, I show that while AI effectively eliminates the first, it does little for the third and may actively worsen it. The scarce resource in enterprise technology was never developer time; it was always the finite capacity of people to understand the systems they depend on. AI just makes that visible. The implication is not that governance should be dismantled, but that its focus should shift from 'can we build this?' to 'what will we choose not to comprehend if we do?'
The Three Forces
In looking at what might change in Enterprise Technology with the advent of powerful Generative AI techniques, it is important to look at three foundational forces which have shaped this area since the 1950s
- Software Development is Expensive (cost of production): Specialists are needed to develop software, and the more software you have which integrates with other software, this cost compounds as changes ‘recurse’ through systems, potentially undoing fundamental assumptions baked into certain components
- Domain knowledge is scarce and hard to transfer (cost of knowledge): Specialists run businesses, and design processes, and these specialists are limited in number and capacity. Further, there tends to be a ‘double hit’ of specialist needed – the intersection of the domain and the specifics of the company or industry the company works in.
- System complexity has cognitive limits (cost of comprehension): There’s a limit to how much any one person or team can hold in their minds and usefully access during decision making, as this limit is approached or exceeded you start to get sub-optimal decision making where the implications of decisions were not known or fully considered
These forces gave rise to the structures generally accepted as ‘good enterprise IT’ today.
The Equilibrium That Resulted
Forces 1 and 2, along with the fundamental idea of economic specialisation resulted in the large software houses and platform companies like SAP, Oracle and ServiceNow. Their need to have broad market appeal meant they leant into configuration (and to some extent customisation) as a product strategy. And these two aspects (software platforms and configurability) further led to Enterprise Architecture as a governance mechanism, really to look after the concern of Force 3, and to try to manage the resulting complexity.
It is ironic the need for configuration and customisation was there despite ‘best practice’ being encoded into these software systems, suggesting that there was a tension before AI even came along. It is worth noting that if there has always been friction between vanilla ‘best practice’ and organisational specifics, then the value of COTS is not the encoded knowledge, rather it is the reduction in the number of things technology teams have to comprehend.
The AI Disruption
The technology development world has been turned on its head with the advent of Generative AI, and especially in the last 3 months with the orders of magnitude increase in the capability of models like Anthropic’s Claude Opus 4.6. There are examples of working C compilers, working web browsers and even replicas of complex products like Okta, Jira and Google Docs being built by teams of autonomous agents.
What this has done is dramatically reduce (effectively eliminate) my Force 1 (cost of production), the marginal cost of development is now so close to zero it may as well be zero. This has led to the huge proliferation of AI generated code and other content, a phenomenon sometimes called ‘AI-slop’ because as well as being high volume, it is also at times of questionable usefulness and quality.
It is worth noting at this point, that you can nuance cost of production to cost of initial production, especially looking at my examples from earlier. The C compiler and web are complex software produced for little initial cost; however, they are demos and we do not have reliable results that the ongoing cost of maintaining them is less.
These technologies also partially address Force 2 (cost of knowledge) as large language models (the technology behind most Generative AI) do encode some domain knowledge, albeit imperfectly.
On the flip side, such technologies do nothing for Force 3 (cost of comprehension) and there is a plausible argument to say they worsen it as if everyone can build, everyone will build, and complexity explodes. A valid push back on this position is that AI technologies could help reduce cost of comprehension, by aiding people to understand systems they did not build, after all, such tools can summarise million plus line code bases in seconds. However, this misses the point that summarisation is not comprehension, it is in the details of interactions that issues surface, and no amount of summarisation will help you predict emergent behaviours (third, fourth, nth order) across system boundaries.
Despite this, increasing pressure is being placed on IT departments and especially architects to ‘get out of the way’ because now the cost of production has been eliminated the main reason for most control mechanisms has been eliminated. So, we must ask “are they right?” in a world where the marginal cost of development is zero, do any of our traditional approaches make sense?
The Balancing Model
To answer that question, I propose a simple model , where the total cost of a technology capability over time (T) is:
T = D + K + M + C
Where D is development cost, K is knowledge acquisition cost, M is maintenance cost and C is comprehension cost (which we know scales non-linearly with the number of distinct components which interact).
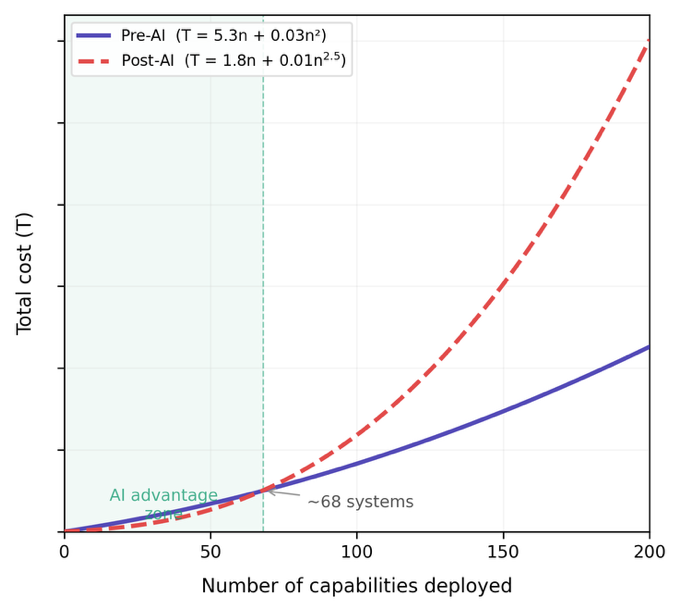
This model uses illustrative coefficients. Pre-AI total cost per capability reflects high development cost (D=3.5), moderate knowledge acquisition (K=1.0) and low maintenance (M=0.8), with comprehension cost scaling as 0.03n² (pairwise interactions in a governed portfolio). Post-AI reflects near-zero development (D=0.1), reduced knowledge acquisition (K=0.5) and higher maintenance (M=1.2), with comprehension cost scaling as 0.01n^2.5, reflecting higher-order cascading effects across ungoverned, independently built systems. The crossover at ~68 systems and the relative magnitudes are illustrative; the key insight is structural: that super-linear comprehension costs inevitably dominate linear development savings at scale.
In the traditional world (pre-AI), D is high, so you minimise the number of things you build, this keeps C lower (manageable) as a side effect. Simultaneously, a buy-and-configure approach optimises for a lower D and K.
AI drops D dramatically (arguably to nearly 0), but M does not disappear, in-fact it could be argued the need for maintenance and the effort involved in that maintenance increased when built by people who do not deeply understand what has been built. We can reasonably expect K to drop, especially as related to fact-based reasoning, but it will not diminish to 0 and indeed we know that LLMs imperfectly encode knowledge. The killer issue is C, comprehension cost, which increases super-linearly as large numbers of interacting and self-built systems are added to the technology landscape.
This model predicts that a rational team or organisation would exploit the cheaper development cost D where the complexity C impact is contained (isolated capabilities), while maintaining architectural governance to prevent C from exploding. This suggests that “everything we knew is wrong” is overblown hyperbole, and it also suggests that architectural governance needs to shift focus from cost of development towards organisations having finite comprehension capacity, which should be harnessed in ways which bring the greatest returns.
While this model is additive, which implies the costs are independent of each other, the reality is more complex for example greater C drives greater M, however for the purposes of this discussion, the simpler model is adequate and supports us in drawing high level conclusions.
So where does that leave us?
This paper started by asking “is everything we knew about Enterprise Technology wrong?”
I conclude that it is not, however the framing in most organisations that cost is main thing holding back greater development of customised software does contribute to the emerging narrative that as that marginal cost diminishes to zero, we should take the brakes off. This is further not helped by the fact that in most organisations this understanding of cost is unnuanced and largely focused on my Force 1, cost of production.
Technology Architecture needs to play a vital role in guarding an organisation’s precious resources, for a long time, that has been money, and the typical scarcity of money has masked the next most scarce resource, comprehension, or mental bandwidth. In a world where anybody can build anything for little input cost, we should be framing the decisions not around “can we”, but “should we” and the main area of assessment should be related to cost of comprehension, and looking at “what will we be choosing not to comprehend, if we spend our resources on this?”
-- Richard, May 2026