

Technology delivery risk
Delivering technology projects is risky, where 'risky' means that sometimes (often) those projects either completely or partially fail to yield their intended benefits. This could be for a multitude of reasons, including budget or time overflow (late or too costly), incorrect specifications (design) or failing to build to the specifications.
For the purpose of this article, I’m defining this risk broadly, where technology delivery risk means any failure to meet the intended goals of a project, and these goals could include the reputation and profit margins of a service provider who was engaged to do the work for a client.
Often, companies will attempt to quantify such risks and hold contingencies to cover the eventuality that these risks materialise. These contingencies can take the form of extra budget, resourcing or schedule time - but often is held as budget, which is seen as a proxy for the other two items.
From my time in the world of IT delivery, I’ve come to realise that much of how risk is judged and attempted to be mitigated is ineffective, and despite large bodies of evidence confirming this, we continue to do the same.
“We’ll worry about tomorrow, tomorrow” We said that yesterday - Leo McGarry in The West Wing
A survey of failure
It is no secret that technology projects fail, many of them in high profile circumstances and there have been a number of surveys and articles written on this, but just so you know I’m not making it up, here are some stats:
- McKinsey research has found that 25 to 40 percent of programs exceed their budget or schedule by more than 50 percent
- BCG have said they think the average rate of success in large digital projects and programs is 30 percent or less
Attempts at judging risk
Many companies, especially service providers (also known as system integrators or SIs) who build technology for living have what they consider to be sophisticated models for judging risk. These are based on answering questions about a piece of work which in turn creates a ‘risk score’ and this score is then used to decide on the minimum contingencies that should be held (typically money) by the project. It sounds simple and like it should work: risk level drives contingency setting, and this contingency is then drawn down when those risks eventuate. Right? … Wrong.
Bias and fallacies
First a digression. In Daniel Kahneman’s excellent book, Thinking Fast and Slow, he recounts an example from his own experience of writing a psychology textbook along with a number of his peers. This group all thought that despite evidence telling them it would take seven years and have a 30% chance of failure, that they would complete the task in 2 years and have little chance of failure. This is a vivid example of the planning fallacy, the tendency that humans have to not consider the outside view when evaluating the likelihood of an event, and it is made all the more vivid considering the skills and experience of the group who made the error in this example.
Human thought is subject to many structural biases that most people are unaware of. These biases present in different ways, but they fundamentally affect how we answer questions. These are relevant because when we are answering questions about the risk of a project, they come into play as well. For example:
- Availability bias: if something comes easily to mind, it is more likely
- Cognitive ease: a general bias towards things which are less taxing to think about
- Substitution: answering a different question than was asked
- Intensity matching: using a value on one scale to imply a value on another scale
- Coherence: stories which are well put together seem more plausible and therefore more acceptable
- Halo effect: if I like a person (or consider them to be a ‘good person’) then things they do or plan to do inherit this halo
- Base rate neglect: failing to take into consideration prior rates of occurrence of given outcomes
- The planning fallacy (described above)
- Theory induced blindness: the tendency to trust theories to the extent that we search for ways of confirming them even when we encounter specific situations which do not match them
In the movie “The Big Short”, an investment strategy is described as “simple and brilliant” - that people hate to think about bad things happening so they often underestimate their likelihood - and people will sell options cheaply for these long shots. This observation has a grounding in real psychology: the ‘certainty’ and ‘possibility’ effects which lead people to overweight unlikely events and underweight likely events. This can translate over-indexing on less likely failure modes and a lack of preparedness for likely failure scenarios.
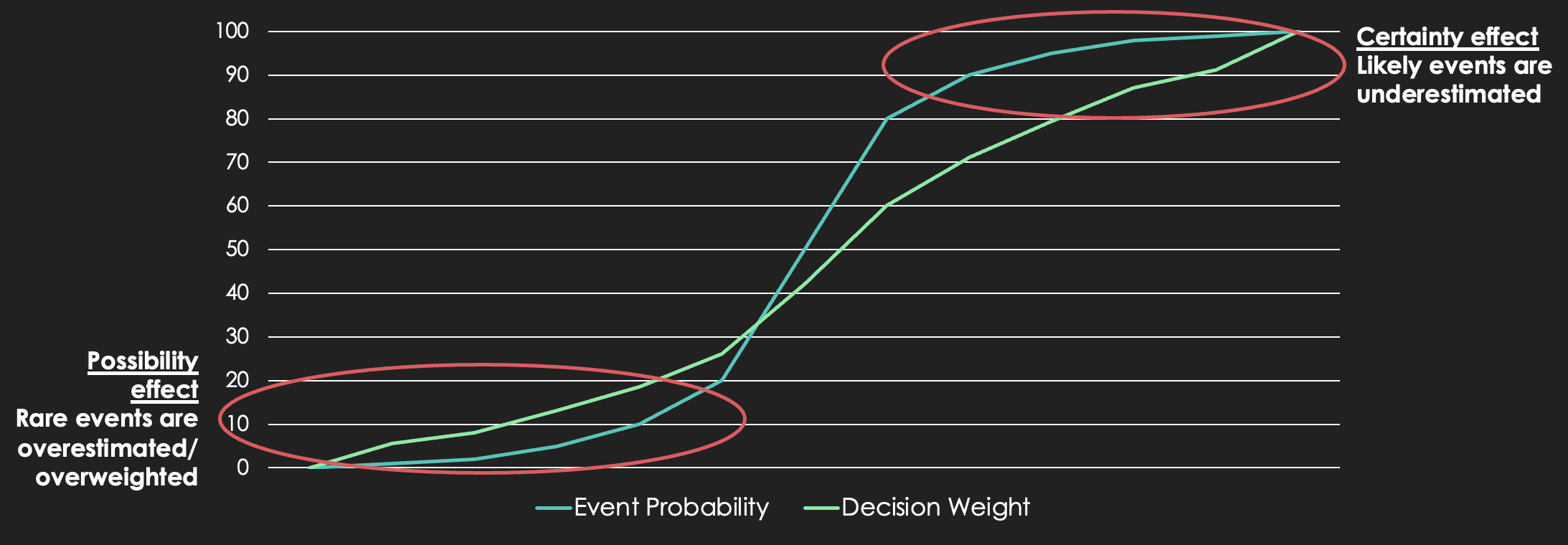
As well as these unconscious aspects of thought, we also have to consider that risk judgement often happens during the sales or initiation phase of a project. At this time the people who are doing the judging are the same people who are the protagonists for the project and they have an interest therefore in representing it in the most positive light and this often means portraying the project with reduced risk.
Low validity environments
Prediction is known to be hard, and we often get our predictions wrong. Just think about pundits on TV speculating about markets, politics and sports outcomes - how often are they right? You probably don’t know, but many studies have said that their predictions are worse than coin tosses. Distressingly, studies of professionals who make similar long range predictions like CFOs and medical doctors have shown similar outcomes.
There have been some academic studies into prediction and intuitive decision making, looking at why some people seem to be very good at ‘gut decisions’ and others (like the pundits I mentioned above) are not. One such study is by Gary Klein and Daniel Kahneman called 'Conditions for Intuitive Expertise: A Failure To Disagree'. Despite coming from opposite sides of the debate, Klein and Kahneman found common ground on the concept of ‘low and high validity environments’. They described low validity environments as those where there is a high degree of unpredictability and uncertainty (randomness) which is typically coupled with a long time period between a prediction being made and getting feedback on whether it was correct or not. Such environments are often specific to particular situations and therefore each decision or prediction to be made bears little resemblance to others made in the past.
I consider that most technology delivery projects qualify as low validity environments. They are typically long in duration, involve many parties (people and companies), and are affected by events which cannot be predicted: people resign or get sick, companies change direction, requirements altered, competitors can spring up and suppliers can go out of business.
All of this means that relying on expert judgement to predict project success is likely to not be better than tossing a coin.
What happens in difficult times
Most of the time we deal with risk in delivery projects by setting aside a contingency for those risks. This can be thought of as insurance, for example extra time in the schedule or extra resourcing (or money) for completion of tasks. We tell ourselves that this extra time or money will be used to deal with the unexpected. Most of the time this is money, as often projects have hard deadlines, so extra time is not an option. In a world consisting of 'econs' (people who behave 100% rationally at all times) this might work, we would determine the likelihood of a risk, we would determine the money needed to deal with the risk (its cost) and finally we would determine the expected value of all the risks - the sum of the products of the risk probabilities and costs and this would become our contingency.
Except we are not econs we are humans - so even when following such a structured process we are likely to be subject to biases and fallacies, to underweight likely events and underestimate their costs. Which leads us to not have enough contingency set aside.
There is a more fundamental problem though, and that is that contingency does not provide for the truly scarce resource when things get tough: bandwidth.
Scarcity
In their book: Scarcity the authors Sendhil Mullainathan and Eldar Shafir break down the fascinating psychology of scarcity and not having enough money, time or social interactions. They find that the way we cope with the three kinds of scarcity is very similar, and that in such situations we tend to focus more, but at the same time we 'tunnel', which puts a very real tax on our cognitive bandwidth. They found that this tunnelling behaviour makes us focus on actions and solutions that have benefits inside the tunnel, but this comes at the cost of completely ignoring tasks, actions and solutions which have benefits which fall outside of the tunnel. And this is not a conscious ignorance, those things just don’t occur to us.
You might have your own examples of this, a project not going well or a looming deadline that you keep thinking about while at your child’s birthday party.. you are not really there, your thoughts keep returning to this one thing.
This is relevant because many technology delivery projects have a scarce resource in common: time. We have hard deadlines, and as such when those deadlines are at risk we start focusing and tunnelling. We neglect the things that we should still do to keep us in good shape for later phases of the project - why: not through lack of skill or care, but because we are tunnelling.
As a result of the schedule being fixed, we keep money aside, thinking that if we get into trouble we can use that money to bring on additional people, and we divide the work over that larger group of people and we get back on track. But this view neglects scarcity and tunnelling, that the people already in the team are low on bandwidth and that they are unlikely to be able to accept new help: the problem exists in front of them, the benefits of the new person coming in lie outside the tunnel, after they are trained up on the specifics of this project - and on top of that, the existing team is the one that needs to do the training, they see that as a cost.
There are other very interesting findings from Sendhil and Eldar’s work which come into play for us as well. Projects are often split into phases - a discovery phase, a design phase, a build phase and so on. Even when agile methods are used, there are chunks of time carved up - high level phases of work and then sprints in which work is done. What they found is that once people who have been in a scarce environment move into one of temporary abundance, for example you complete a piece of work for a deadline and then move to the next, that this does not necessarily translate into the resumption of normal service. People can relax (which is very necessary) and then a series of ‘micro shocks’ (people being ill, somebody leaving, an extra bit of work getting thrown in) can slowly eat away at the available slack until you are back in difficulty again.
So once a project has got itself into trouble, it is likely to stay that way through a combination of the effects of scarcity and the odd impacts of mental accounting which see people back in surplus again fail to consider how that surplus can be spent in another mental account (another phase of the project).
Management to the rescue…
Once a project is in trouble, people take notice - watch lists are created, and senior management want to get involved and help. This help tends to take the form of extra reporting, more detailed status reports and extra meetings where senior managers and executives want to be aware of all the details and happenings in the project. I’ve been in a number of these (from the project point-of-view) in my career. I don’t doubt that they are well intentioned, but the approach ignores the scarce resource: bandwidth, and in fact, it is an extra burden on bandwidth - it creates another thing to tunnel on - the next meeting, these are also highly personally stressful as you are in front of your leaders, the same people who determine your career progression.
The senior leaders and execs in these sessions can often get frustrated at what they see as a lack of foresight, care or people not thinking about the bigger picture. But the fact is they can’t, they are tunnelled, and not getting the help they need.
So we are in a perfect storm, we had a plan with structural issues (as a result of human biases and fallacies), we had misjudged the risk and not held enough (or the right type of) contingency, the team is late and tunnelling and we have ‘help’ in the form of extra work from senior management who are wanting to ensure the success of the project.
So what can we do then?
If you are thinking this is just me whining, then thanks for hanging on this far - because this is where I get to my answers. I think there is a better way, and I summarise it as:
- Determining structural risk
- Continually evaluating risk
- Bandwidth contingency
Structural Risk
What I mean by ‘structural risk’ is the risk inherent to carrying our a project based on facts, rather than beliefs. It is the risk embedded in a project simply by evaluating it objectively, for example:
- Has the company delivered a project like this before?
- Has the team done this before?
- Has such a project of this size and scope been delivered for this time and cost budget before?
- Is the team size and shape matching the effort requirements
- How busy are the people working on the project expected to be, do they have slack for other tasks which might (will) pop up?
We can look into projects delivered in the past and compare our project to them, in order to give us a sense for the likelihood of success based on real data. This is referred to as going back to base rates - and it is the correct way to evaluate a question in the absence of any other information. Here’s an example
Acme Corporation is a large company and at any one time they have between 10 and 20 large projects running. These projects span multiple years and typically have budgets of tens of millions of dollars. Most projects (~60%) are delivered successfully meaning within time and cost expectations. Some are late and some are over budget.
Acme Corporation is about to implement a new global payroll system, covering their 400,000 staff and executives. It is expected to cost $50m and take 2 years. Acme have recently run similar projects touching HR systems and have been successful.
If I asked you, what’s the likelihood of success of this project you might consider the profile above and say “high”, although it is complex and expensive, they have recently delivered similar projects successfully. I would look at this and say 60%, because the only concrete piece of information we have is that they have an average success rate of 60%. This is the correct approach when you have little information, you start with the base rate and then you can apply the other facts you have (or find) to move yourself away from the average.
This is not easy for most companies, as they do not keep detailed records on how projects were planned, estimated and staffed, however once this is done, and done consistently it will give you a large database against which to compare your upcoming projects so you can determine their inherent risk based on real historic performance for similar work.
As much as possible I also believe in using datasets which go beyond an individual company - this ‘outside-in’ view is very important in having a somewhat impartial view.
Continual Risk Evaluation
For a lot of companies, performing a risk evaluation and setting contingencies for a project is seen as a one-off activity. This approach is flawed, flawed for the reasons I’ve laid out in this article (human decision making failures) but also flawed because the world is constantly changing and each of those changes might have an impact on the risk profile of your work. Instead I’m advocating for a continual evaluation of risk, so that as events unfold we consider the revised likelihood of success or failure and then act accordingly.
In his book, “The Signal and the Noise” Nate Silver talks about successes and failures in prediction and lays out his approach to solving for the failures. He’s an advocate of Bayesian thinking, and I believe this is the right approach for our continual risk evaluation models as well.
Thomas Bayes was an English statistician and minister, born in the 1700s, who created an approach to thinking about probabilistic relations which we refer to today as Bayes’ theorem. It works for us on the basis that you can estimate three quantities:
- What’s called the prior probability, in our case the estimate of the likelihood our project is not successful. This should be as objective as possible, and ideally based on data on the outcomes of projects with similar characteristics
-
Then based on events unfolding in the project, we estimate:
- The probability of the event occurring if our hypothesis (the project fails) is true
- The probability of the event occurring if our hypothesis (the project fails) is false
Here’s an example looking at a scenario where we have missed a design milestone in our project. I have borrowed the tabular representation from Nate Silver’s book.
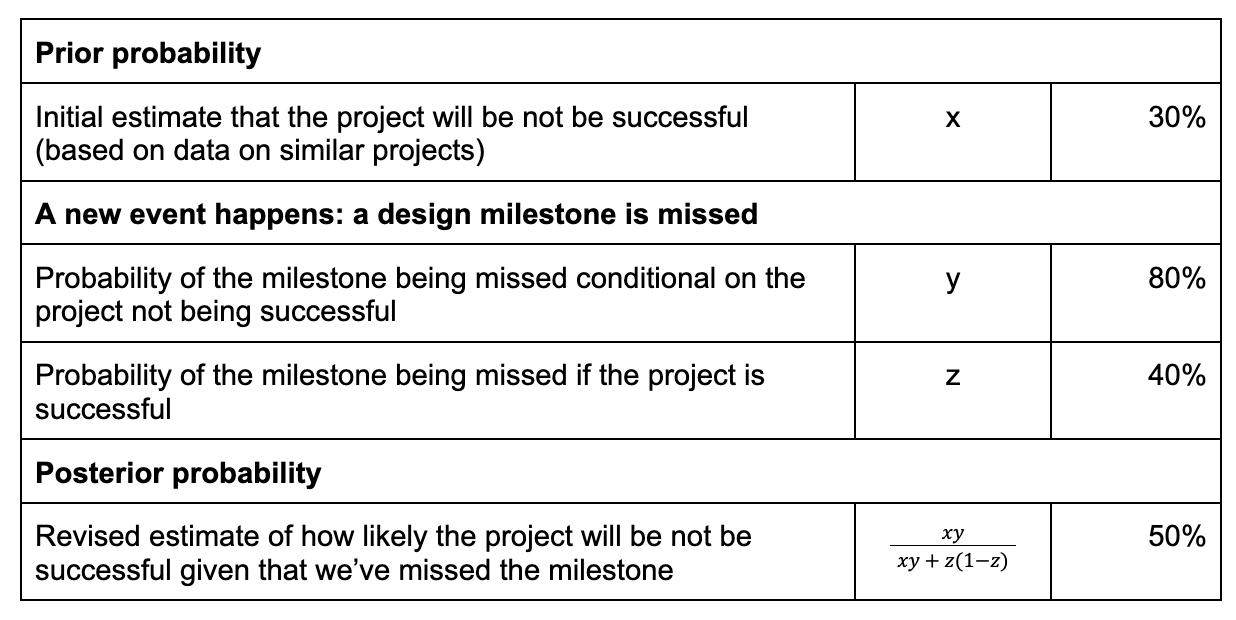
Applying this technique, using the same detailed data that we have kept from our other projects will allow us to answer the question “what’s the likelihood that we fail given that xyz has happened or not happened?”.
It can be expanded to be a continual process which is maintaining a running estimate of the likelihood of project success or failure, and adjusting this as the events of the project unfold. A key to this approach being successful is keeping rich data on how projects are designed, estimated and resourced as well as detailed records on what transpires in those projects when they are in delivery.
Bandwidth contingency
And so we get to the final part of my approach, once we have a view of how likely it is that things go wrong, putting in place mitigations to try to prevent it.
As I mentioned earlier, most project contingencies take the form of extra money, which is held separately from the project budget and used to pay for extra people to come and join the team when things are going wrong. Contingency can also take the form of slack time in the schedule, but in my view this is rarer and also easily used up for non-critical reasons.
How contingency is held and the approvals needed to use it are an issue in my view. I’ve seen examples where not using contingency is celebrated, and people working on such projects are rewarded. It creates a culture where it is a taboo to use contingency, and it makes it more likely that people will not put their hands up to ask for help. I also consider that because of scarcity and tunnelling, adding people to a team which is bandwidth constrained is not really going to solve the problem.
Instead I advocate for contingency being planned into the work in the form of not having people more than 60 or 70% busy. This gives them the room to deal with the micro-shocks that come along (absence, illness, other tasks) without immediate impacts to project deliverables and the schedule/budget. Combining this with the continual evaluation of risk, which is looking ahead at the future phases, gives time to add to or otherwise reconfigure a team so that it has enough slack for the new issues which might come up, so we can keep our team at our target ‘busyness’ of 60-70%.
Conclusion
This was a long article, but in summary I believe we will have much better rates of technology project success when we:
- Use real data and an ‘outside-in’ view to judge inherent and structural risk in projects
- Determine mitigation strategies (contingencies) based on this inherent risk
- Continually evaluate risk with data and apply Bayesian reasoning
- Apply mitigations which take into consideration tunnelling and the effects of time scarcity
- Collect rich data and use it to improve risk evaluation and mitigations in the future
-- Richard, Mar 2023